2009-09-13 Machine Tag Taxonomy and Binomial Nomenclature
Machine Tag Taxonomy and Binomial Nomenclature
This is not a secret that I'm interested in botany and biology in general. When I'm shooting some pictures of the wild life, I'm always trying to classify properly the picture taken. Classification is very important when you are trying to protect the life around you. Especially when you are gardening, it happens that you have some bad surprise because a plant nursery used the same common name for two different plants. That's one of the reason why the use of binomial nomenclature is highly recommended.
I have gathered some notes on my use of machine tag for biology taxonomy. So you can express easily the classification on web services using tagging (like flickr or del.icio.us) a machine tag that can be read by human and by machine (read information automated systems) :
taxonomy:binomial="Asperula arvensis"
But finding the proper binomial name and especially, the proper spelling is not always easy. So I made a hack around agrep to find the proper spelling of a binomial name using a part of the official catalogue of life provided by ITIS.
The full text dump (around 10MB) of the binomial name extracted from the catalogue of life is also available. Without having such research data available, it would have been very difficult to build such an exhaustive catalogue.That's not a coincidence if the cover page of the latest Nature is about Data in research. Data is a critical part of the future of research but it needs to be easily accessible with the proper free license (just like free software).
Tags: tagging tag folksonomy classification reference machinetag machinetags triple_tag biology life binomial

2009-07-31-The Yin and Yang Of Information Security
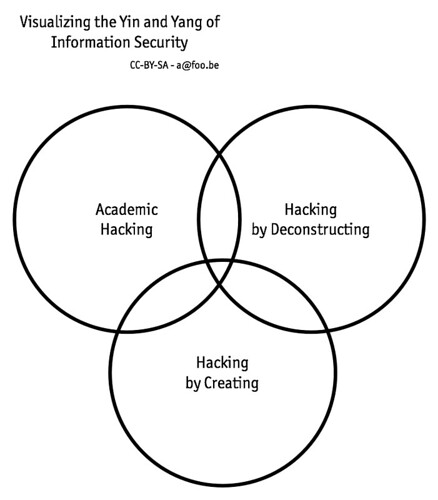
Visualizing the Yin and Yang of Information Security. Working in the information security field, I had some difficulties to explain the equilibrium I tried to reach. Stuck (again) in a traffic jam, I quickly drew the following three circles representing the three kind of "information security" approach. I somehow work in the three circles and often trying to reconcile the three with some large failure but also some success.
Being in the centre is very hard, you have to balance between proper implementation (the creation part), proper implementation against "deconstruction"/attacks while keeping an eye on the scientific input.
In the chapter 46 of the Myths of Security, John Viega is nicely explaining when you are just in the academic hacking circle without going close to the two other circles. You are doing academic novelty that no one can use, implement and attack. So the impact of your academic research is only the academic circle and nothing else.
When Linus Torvalds is stating "we should not glorify security monkey", this is the classical behaviour of staying in the "de constructing" circle without trying to find something creative and/or academic to solve the security issue.
When Wietse Venema is explaining that you should write small independent without modifying existing program to not affect the integrity of the others program, it's when you are creating a new software without taking into account the "de constructing" attacks on your software or the scientific background to make your software with a good level of formal correctness.
I'm the first to make the mistake to be contained in a single circle but you must force yourself to touch the two other circles in some ways. Information security is difficult but this equilibrium (academic, creativity and deconstruction) is difficult to reach. When you are close to reach to it, this is really a great moment…
Tags: academic software infosec stability
2009-05-16 Diversity and Stability The Case Of Hedges
For my recent birthday, I received a nice book called "Plantes des haies champêtres" (plant from the natural hedges) written by Christian Cogneaux. The book is a directory of the whole plant usually composing the natural hedges. On the form, the layout and typography of the book is clear and easy to read (the form is also important to render a book more interesting). The photos made by Bernard Gambier are really beautiful and tight to the spirit of the book. The content itself is useful (especially if you want to keep or create new natural hedges in your garden or land) and provide an exhaustive overview of the species available and common to natural hedges. But what's the relationship with diversity and stability in my blog title? good question. When reading the introduction about the importance of preserving natural hedges, I immediately thought about the scientific reason behind the conversation of natural hedges.
An natural hedge with its heterogeneity provide a nice ecological system to reach a "equilibrium stability". As demonstrated by the zoologist Charles Elton, a more diverse community provides more resilience while changes are introduced (like the introduction of new species or predators). Natural hedges provide a nice complex system with the abundance of species allowing to increase the general stability. If the topic of diversity-stability interests you, there is an excellent article from Nature on the diversity stability topic in Biology.
If you want to participate to biodiversity, when you are thinking of planting new hedges, consider to not use a single specie for your hedge. On one hand, you are introducing more risk to completely loose the hedge (e.g. when the hedge is sensible to a single predator). On the second hand, using various species help to increase biodiversity and protecting the surrounding nature. There is also nice effect of diverse natural edge : a natural edge with various species is nicer to look at than a monotonic green wall-like edge.
For the information security freaks reading my humble blog, there is the collateral discussion about diversity in information system as explained in the article : The Evolution of Security : What can nature tell us about how best to manage our risks?. But this is another story…
Tags: biodiversity ecology hedges diversity stability
 On the cover, you can see a nice Lonicera (very common on natural hedges).
On the cover, you can see a nice Lonicera (very common on natural hedges).
2009-02-22 Society Economy and Metrics
Society, Economy and Metrics : Rethinking Economy In The Society
When an idea is confronted over time, there is a high risk (but that's part of the game) of destruction. If the idea is coming more and more stronger over this confrontation process, there is the possibility of the something new to be created over time. The past few months, I read again André Gorz especially Écologica and L'immatériel : Connaissance, valeur et capital. Surprised by his consistency and ability to surround the important topics in the information society, there is a common recurring concept always popping up in his works : the metric and especially the lack of universal measure (called "étalon de mesure") in the information society. Gorz pointed the issue with the capital and the operation of the economy trying to capitalize on the "intangible capital". Reading his works right now is very interesting especially that he was really pointing the risks of creating economic bubble while trying to apply the capitalism techniques of tangible asset against the intangible.
Looking back, the idea of "universal metric" in the information society was somehow already hitting my mind with the following post and projects : Wiki Creativity Index, Innovation Metric (especially that the clumsy patent system is the only metric in use) and Creativity Metrics Are Needed. Project like Ohloh is already providing a specific answer to quantify the activity in the free software community. We are still far away(?) from an "universal metric" but when it will possible to link the respective activity of a human being with an exchangeable "money" (like bitcoin), we could have the possibility of growing without impacting the natural resources and funding the society with a real citizenship.
2009-01-02 Google Books And Europeana Are Killing Public Domain
More than two years ago, I made a blog entry about "Google Books Killing Public Domain" where Google is adding an additional clause to render public domain works into (again) the private circle by limiting the use to private use all public domain works scanned by Google.
Reading an Interview (sorry in French) of Jean-Noël Jeanneney, Mr Jeanneney is very proud of the Europeana digital library competing with Google Books. That's nice to see competition but is it really different from Google Books? No, Europeana is also transforming public domain works into proprietary works. Just have a look at Europeana's terms of service (copying section), they make the same mistake.
I had a lot of arguments especially during a conference held by the BNF about digital libraries, their arguments is about the cost of scanning or the "add of value" in scanning those public domains works. Sorry to say that but this is pure fiction (to be polite ;-), there is nothing like "adding value" while scanning an old public domain book. If you want to create wealth for the benefit of Society, please release public domain works as public domain. You'll see unexpected use (including commercial use) of those works and that will benefit everyone even the Libraries doing the scanning.
If you want to be ahead (I'm talking to Europeana or even Google) and help everyone, please leave the public domain works in the public domain.

2008-12-24 Oddmuse Wiki Using Git
If you are a frequent reader of my delicious feeds, you can see my addiction regarding wiki and git. But I never found a wiki similar to Oddmuse in terms of functionalities and dynamism relying on git. Before Christmas, I wanted to have something working… to post this blog entry in git. The process is very simple : oddmuse2git import the raw pages from Oddmuse into a the master branch of a local git repository. I'm using another branch local (that I merge/rebase regularly with master (while I'm doing edit via the HTTP)) to make local edit and pushing the update (a simple git-rev-list --reverse against the master) to the Oddmuse wiki. The two scripts (oddmuse2git git2oddmuse) are available. Ok it's quick-and-dirty(tm) but it works. There is space for improvements especially while getting the Oddmuse update using RSS to avoid fetching all the pages.
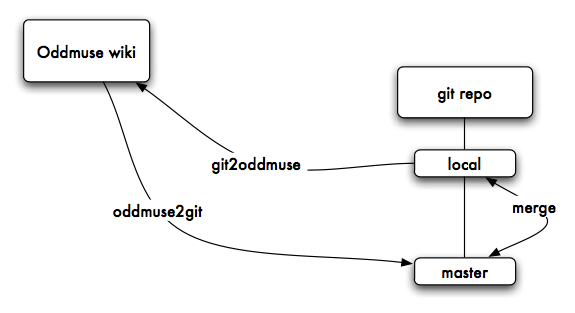
Update - 20th December 2008 : I imported communitywiki.org using my oddmuse2git and update seems to work as expected. If you want clone it :
git clone git://git.quuxlabs.com/communitywiki/
I also updated the script to handle update (using the rc action from Oddmuse) to only fetch the latest updates. For more information about Oddmuse and Git.
2008-12-21 Scientific Publications and Proving Empirical Results
Reading scientific/academic publications in computer science can be frustrating due to various reasons. But the most frequent reason is the inability to reproduce the results described in a paper due to the lack of the software and tools to reproduce the empirical analysis described. You can regularly read reference in papers to internal software used for the analysis or survey but the paper lacks a link to download the software. Very often, I shared this frustration with my (work and academic) colleague but I was always expecting a more formal paper describing this major issue in scientific publication especially in computer science.
By sheer luck, I hit a paper called "Empiricism is Not a Matter of Faith" written by Ted Pedersen published in Computational Linguistics Volume 34, Issue 3 of September 2008. I want to share with you the conclusion of the article :
However, the other path is to accept (and in fact insist) that highly detailed empirical studies must be reproducible to be credible, and that it is unreasonable to expect that reproducibility to be possible based on the description provided in a publication. Thus, releasing software that makes it easy to reproduce and modify experiments should be an essential part of the publication process, to the point where we might one day only accept for publication articles that are accompanied by working software that allows for immediate and reliable reproduction of results.
The paper from Ted Pedersen is clear and concise, I couldn't explain better that. I hope it will become a requirement in any open access publication to add the free software (along with the process) used to make the experiments. Science at large could only gain from such disclosure. Open access should better integrate such requirements (e.g. reproducibility of the experiments) to attract more academic people from computer science. Just Imagine the excellent arxiv.org also including a requirements in paper submission to include a link to the free software and process used to make the experiments, that would be great.
Tags: openaccess research education freesoftware
2008-12-13 Creativity In Free Software
Reading the blog of Frédéric Péters, I stumbled upon his post called "Vers l'infini et au-delà !". I quickly commented as I share a similar feeling about the recent development of the relationship between software "industries" and free software. Frédéric pointed out the recent "2020 FLOSS Roadmap" report where the roadmap is more a tentative to be close to the fuzzy and vague Magic Quadrant than something really coming from the free software community (yep, the community is not only composed of "industrial consortium" even if this report is trying to give this idea).
My feeling is the following : there are no way to predict the future especially while we are talking about (free) software evolution. Roadmaps are more close to science-fiction books (I prefer to read science-fiction books that's more fun) than something else. Why it's like that? Just because software development is a trial-and-error process and especially in the free software community. Free software users also choose their free software by trial-and-error… how can you easily predict the state of free software in 2020 when a trial-and-error process is in use? This reminded me again of the post from Linus Torvalds about "sheer luck" design of the Linux kernel. To quote him :
And don't EVER make the mistake that you can design something better than what you get from ruthless massively parallel trial-and-error with a feedback cycle. That's giving your intelligence _much_ too much credit.
Projecting in 2020 what will be the Free Software is just a joke. What we really need to do to ensure a future to free software is to ensure the diversity and the creativity dynamic in the community. Creation and development of free software without boundaries or limitation is critical to ensure a free future. New free software development often comes from individuals and not often from large industrial consortium… So the roadmap is easy : "Resist and create free software".

Tags: freesoftware diversity biology freedom
2008-11-16 It s Time To Join APRIL
It's time to join APRIL, the GNU will thank you.
It's time to join APRIL… If you have an organization to join in France doing the promotion of free software and its philosophy. There is only one… this is APRIL. The GNU will thank you (as you can see on the picture, he is already thanking me of being a member, even if I'm from Belgium).

Tags : gnu freedom april freesoftware free_software
2008-11-08 Copyleft Licenses and Activating The Perpetual Loop
When I first touched free software (that was a long time ago.. I'm feeling old Today) that was mainly for a technical reason. The technical reason quickly shifted to the ethical implication of free software and its relation with freedom in general. The comfort of copyleft licensing is a like a promise to me : "keeping "information" eternally free". My view is that copylefted information (from free software to free art) is just like a biotope where the environmental condition (in this case copyleft licensing) helps to create a living place. The copyleft is a guarantee for the biotope to have a sufficient input to grow and to provide a good fertilizer. In the past few years, the ecological system of copyleft has been working quite well but the main reason (IMHO) for its limited grow is the incompatibility between the copyleft-type licensing as those licenses are often mutually exclusive.
I'm not in favor of the excessive proliferation of copyleft-type license increasing the legal complexity while not improving the life activity in the copyleft biotope. That's why I'm using the following licensing statement :
This work is licensed to you under at least version 2 of the GNU General Public License. Alternatively, you may choose to receive this work under any other license that grants the right to use, copy, modify, and/or distribute the work, as long as that license imposes the restriction that derivative works have to grant the same rights and impose the same restriction. For example, you may choose to receive this work under the GNU Free Documentation License, the CreativeCommons ShareAlike License, the XEmacs manual license, or similar free licenses.
The recent minor extension of the GNU Free Documentation License 1.3 is creating the ability to also use the Creative Commons Share Alike (CC-SA) is going into the direction to improve the biotope interaction. In my view, I never understood why we have different copyleft licenses for at the end any information works like computer programs, images, arts or documentation living in the same biotope. I was willing to use the GNU General Public License for any type of free information works. I'm sure that differences between the type of works will disappear in the future and at the end, we'll have a generic GNU GPL (version 4?) where any copylefted works are included. Life is so beautiful in this biotope that we cannot limit it with incompatible licenses…


